Want to take your brand overseas? Well, most organizations dream of it, and something that helps them turn it into reality is their content. Here’s the thing: great content opens the door to greater opportunities, but what keeps them open is localized content. Does that mean you would have to rebuild your content from scratch for every new market?
Fortunately, today we have capable AI voice dubbing tools that act as a connecting bridge between businesses and a diverse audience by making multilingual communication faster, more natural, and far more accessible.
Although these tools are like a cheat code for brands, statistically, one in five organizations reported experiencing a data breach due to security issues with “shadow AI” (unauthorized AI tools used by employees).
Such reports often raise questions in a user’s mind: Are these AI tools used for dubbing and other operations really worth the risk? Do they actually steal your data?
In this post, we will uncover the answers to these questions and understand how these AI dubbing tools impact your data.
Key Takeaways
Your voice is sensitive data; treat it like a fingerprint, not just some file.
AI tools’ convenience can come with hidden security trade-offs.
Lack of transparency is often a bigger red flag than the technology itself.
Strong access controls and short data retention make a real difference.
Trustworthy AI dubbing tools protect both your content and your identity.
How AI Dubbing Tools Collect, Store, and Process Voice Data
Obviously, to dub your content, the AI tools would need your content, which means accessing your data. Different platforms use varied methods to collect, store, and process your voice data.
1. Collection:
Data can be collected through direct uploads, where the users themselves upload raw audio files; Live capture, which includes recording in-browser or via remote tools; API ingestion, where third parties push audio to the provider; or datasets for model training.
2. Storage:
Temporary staging for short-term storage requirements, long-term archives that allow platforms to keep audio and model artifacts for debugging, reuse, or model improvement, or backups, where cloud providers take snapshots and cross-region redundancy.
3.Processing:
Preprocessing (noise reduction, segmentation, alignment) → Feature extraction (Pitch, timbre, prosody, special features used to create voice fingerprints or embeddings) → Model inference (generation of dubbed audio from source audio plus target language/style parameters) → post-processing (mastering, leveling, lip-sync adjustments).
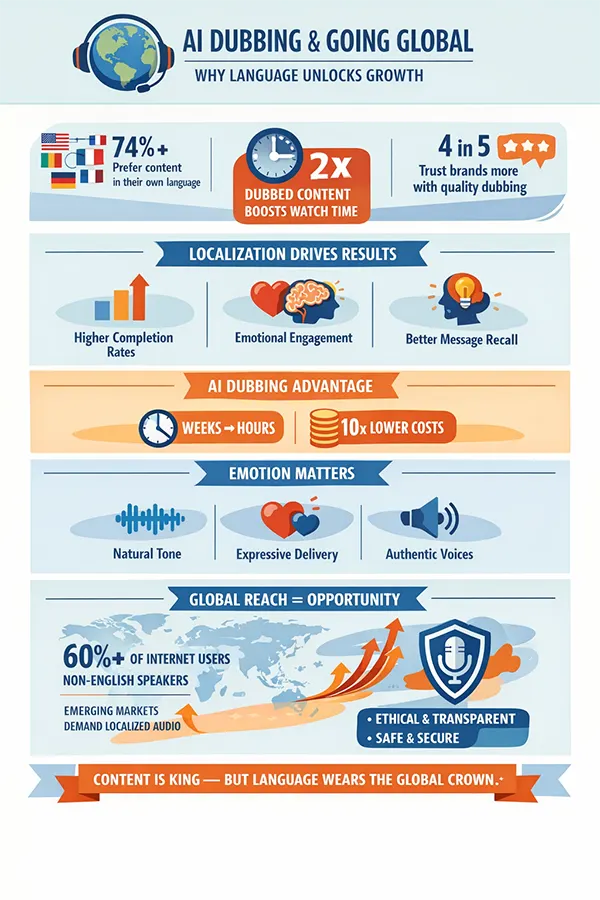
INTERESTING INSIGHTS From the infographic below, understand how language can help you unlock growth.
Risks of Unauthorized Voice Replication and Deepfake Misuse
While these tools are incredibly useful, a heavy cloud of risks of unauthorized voice replication and deepfake misuse always looms over organizations using them.
Identity Misuse: People with malicious intent can easily replicate a real person’s voice with just a 2-second sample speech and then use it for fraudulent calls, impersonation or spread false statements attributed to public figures.
Reputation & Legal Exposure: An individual’s voice can be fabricated and used in content they never consented to, causing immense harm to their reputation or legal disputes.
Misinformation: Deepfaked voices can be used to spread misinformation that could possibly have a damaging impact.
Financial Fraud: Financial fraud is one of the most common types of scams. AI tools make it easier for fraudsters to bypass voice authentication systems.
These factors definitely possess a risk of financial and reputational damage, but they can also take a toll on the victim’s emotional response, making it harder for them to navigate such situations.
Data Retention Practices and Lack Of Transparency in Many AI Tools
Many problematic patterns in AI tools have been detected: default retention, opaque terms, hidden reuse, and insufficient user controls, making it difficult to trust these tools, as these features make it extremely easy for fraudsters and scammers to use your voice for an ulterior motive that may negatively affect you in the future.
The consequences? These data retention practices and lack of transparency snatch the users’ right to make informed consent decisions, and creators may even unknowingly enable permanent use of their voice.
PRO TIP Before uploading any recording to an AI dubbing tool, trim out names, internal discussions, or off-the-script moments. Even small edits can significantly reduce what sensitive information is exposed.
Vulnerabilities in Cloud-Based AI Dubbing Platforms
No doubt, AI dubbing platforms open doors to many opportunities, but what most people ignore is that these doors are also open to numerous vulnerabilities and weaknesses.
A common issue observed is misconfigured storage; many industries have accidentally exposed their sensitive files just because to incorrect settings.
The next risk in line comes from insider access; staff need to access data to perform different functions, but they can quickly turn the organization’s trust into rubbish. If the access control is too broad, the employees can view or copy raw data recordings or models for malicious reasons.
API abuse is another one of the concerns. Dubbing tools often use APIs to upload audio-generated dubbed files. But if this API key gets leaked or stolen, the attackers can quietly download sensitive data or upload malicious content.
Model inversion or membership inference attacks are all about the attackers interacting with an AI model in such a way that it reveals specific information during training or even reconstructs the part of the original speech.
Poor key management and third-party services are some other factors that make it easier for attackers to intercept or access audio files.
Best Practices For Protecting Sensitive Recordings During AI Dubbing
Attackers are always on the watch, waiting for a single slip to make their move and corrupt your data. By incorporating these best practices in your workflows and systems, you can protect sensitive recordings during AI dubbing and strengthen your marketing strategies.
Minimize data collection by uploading only what’s necessary.
End-to-end encryption for protecting audio in transit and at rest. Treat voice embeddings as sensitive artifacts and encrypt them
Leveraging data anonymization and backup tools.
Using clear consent mechanisms for transparency.
Regular security assessments.
Watermarking and provenance metadata to indicate its synthetic origin.
These steps might seem small, but they can protect you from severe reputational and financial damages.
In conclusion, AI dubbing tools are a game-changer for brands as they let them expand their reach, but at the same time, they come with a lot of risks to data integrity. By understanding how a platform collects, stores, and processes the voice data and taking the best practices mentioned above in this post, you can reduce the risks associated with it tenfold.
Frequently Asked Questions
Is cloud-based AI dubbing unsafe by default?
No, cloud platforms themselves aren’t unsafe, but poor security practices can create risks.
Can someone really steal or misuse my voice?
Yes, it is quite possible if your voice data is exposed or poorly protected. Also, voices can be copied, reused, or even cloned if recordings fall into the wrong hands, which is why consent and security matter so much.
What happens to my audio after dubbing is complete?
It depends on the tools you use; some delete the file quickly once the work is done, while others keep them for weeks or even indefinitely for “improvement” purposes.
Are third-party tools a real risk?
Yes, they can be. When audio is shared with transcription services, cloud hosts, or analytics tools, security depends on every link in the chain, not just the main platform.
Data growth has significantly accelerated beyond what most compliance teams can manage, with personal records, financial details, contracts, and emails…